Unlocking the Potential of Your ML Model through Database Solutions
Written on
Chapter 1: Introduction to ML Models and Database Solutions
In our previous discussion, we highlighted a compelling reason to utilize tools like Streamlit and Gradio for swift deployment and management of multiple versions of your Machine Learning (ML) application.
Keep Your ML Models Separate from Application Servers
Transitioning a promising ML model into a fully functional ML product requires careful consideration. We examined the benefits of a model-in-server architecture, especially during the prototyping phase, as it allows for rapid feedback from a select group of trusted testers, helping assess the market viability of your concept.
However, as we concluded, once you move to production, it’s essential to reassess your architecture and extract your ML model from the application server. Challenges such as programming language compatibility, varying scaling requirements, and distinct update cycles make this architecture less suitable for a production environment.
So, what alternatives do we have? Revisiting a basic web application architecture diagram, we can explore three potential options:
- Embed your model directly into the database.
- Move your model to an independent inference server.
- Deploy your model on the edge, closer to the client.
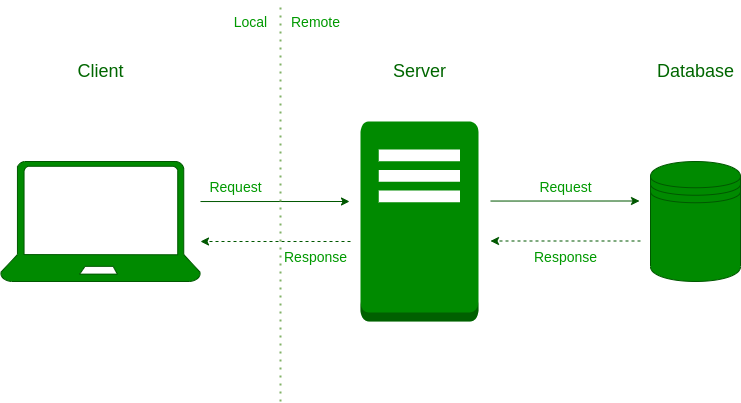
In this article, we will delve into implementing the first option, examining when it is appropriate to choose this approach and the associated advantages and disadvantages.
Chapter 2: Transitioning Your ML Model into the Database
The process of migrating your ML model into the database can be seen as a workaround. Instead of executing code within the database environment, you can periodically run your model offline on new data, saving the results locally and employing a standard ETL (Extract, Transform, Load) process to store predictions in the database.
This strategy represents a straightforward design for deploying a model into production. It alleviates concerns about managing the infrastructure required for your model, performance issues, and latency during requests.
While this may seem like an ideal solution, it’s important to note that it’s not universally applicable. This approach is particularly effective for specific scenarios, including:
- Recommender systems
- Marketing automation
For instance, consider a recommender system that generates a single prediction for each user daily. Imagine a customer entering a store and receiving a recommendation via their smartphone about products that suit their preferences.
In such cases, you can run your model on a daily basis, storing predictions for each user in your database. However, this model-in-database structure may not suffice if real-time predictions are necessary in a dynamic environment. Nevertheless, many recommender systems are successfully implemented this way today, so it’s worth considering if it aligns with your needs.
For marketing automation tasks, such as customer segmentation, this model can be even more advantageous. For example, if you aim to apply an unsupervised learning algorithm to identify user groups for targeted promotional campaigns, you can execute the algorithm once and save the group identifiers in the database.
Advantages of Integrating Your ML Model into the Database
Why should you adopt this approach? The primary benefit is its simplicity. As mentioned earlier, you won’t need to manage infrastructure or worry about performance. You could even run your model on a personal computer and store predictions in a CSV file, which can then be loaded into your database.
Moreover, it scales efficiently. You can leverage the extensive advancements and engineering behind database systems to handle millions of requests, usually resulting in low latency for users.
Disadvantages of This Approach
What are the drawbacks? One significant limitation is that this method does not accommodate complex input types. For example, if users seek insights from an image or text, this challenge becomes apparent.
Additionally, during the training phase, models may encounter data points that are irrelevant during inference, leading to outdated predictions and stale models.
Conclusion
The model-in-database approach serves as one viable option for extracting your ML model from a web server. We explored the types of use cases it suits and weighed its benefits and drawbacks. If your scenario fits this model, it is worth pursuing due to its straightforward implementation and minimal justification for unnecessary complexity.
In our next article, we will discuss when to migrate your model to a dedicated inference server and the steps to achieve this, which is arguably the most prevalent architectural design applicable to nearly every use case.
About the Author
My name is Dimitris Poulopoulos, and I am a machine learning engineer at Arrikto. I have designed and implemented AI and software solutions for prominent clients, including the European Commission, Eurostat, IMF, European Central Bank, OECD, and IKEA.
If you wish to read more about Machine Learning, Deep Learning, Data Science, and DataOps, connect with me on Medium, LinkedIn, or Twitter @james2pl.
Opinions expressed here are solely my own and do not reflect the views of my employer.
The first video titled "Machine Learning on the SQL Server Platform" provides insights into integrating machine learning capabilities with SQL Server, showcasing practical implementations and best practices.
The second video titled "Developing a Solution with SQL Server Machine Learning Services" offers guidance on effectively utilizing SQL Server's machine learning services to enhance data processing and analytics capabilities.