Essential Feature Selection Techniques in Scikit-Learn
Written on
Introduction to Feature Selection
Feature selection plays a vital role in improving model performance by identifying and retaining only the most relevant features. While having more features can initially enhance a model's predictive capabilities, an excessive number can lead to the "Curse of Dimensionality," where the model's performance deteriorates once a certain threshold is crossed. Therefore, selecting only the most predictive features is essential.
It’s important to note that feature selection differs from dimensionality reduction. While both aim to reduce the dataset's complexity, feature selection focuses on choosing which features to keep, whereas dimensionality reduction transforms the data into a new set of input features. For more insights on dimensionality reduction, check out my other articles.
Understanding Feature Selection Methods
In this section, we will explore five effective feature selection techniques available in Scikit-Learn. These methods are user-friendly and highly beneficial for refining your models.
1. Variance Threshold Feature Selection
Variance Thresholding is a straightforward method where features are discarded based on their variance. Features with low variance may not contribute much to the model's predictive power. This method is particularly useful for unsupervised learning, as it does not take into account the target variable.
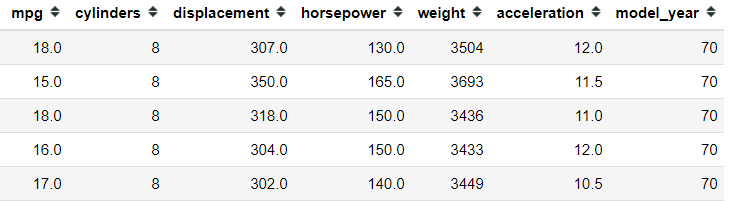
For instance, consider a dataset where we want to apply this method:
import pandas as pd
import seaborn as sns
mpg = sns.load_dataset('mpg').select_dtypes('number')
mpg.head()
Next, we can use the VarianceThreshold class to eliminate low-variance features:
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold=1)
selector.fit(mpg)
mpg.columns[selector.get_support()]
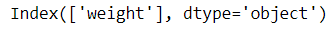
2. Univariate Feature Selection with SelectKBest
This method uses univariate statistical tests to evaluate the importance of features relative to the target variable. The SelectKBest function selects the K features that have the strongest relationship with the dependent variable.
To illustrate, we can use the following code:
mpg = sns.load_dataset('mpg').select_dtypes('number').dropna()
X = mpg.drop('mpg', axis=1)
y = mpg['mpg']
from sklearn.feature_selection import SelectKBest, mutual_info_regression
selector = SelectKBest(mutual_info_regression, k=2)
selector.fit(X, y)
X.columns[selector.get_support()]
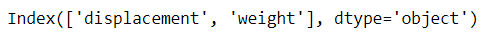
3. Recursive Feature Elimination (RFE)
RFE is a feature selection technique that recursively removes the least important features based on the chosen model's performance. It continues until the desired number of features is reached.
Here’s how to implement RFE using a logistic regression model:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
titanic = sns.load_dataset('titanic')[['survived', 'pclass', 'age', 'parch', 'sibsp', 'fare']].dropna()
X = titanic.drop('survived', axis=1)
y = titanic['survived']
rfe_selector = RFE(estimator=LogisticRegression(), n_features_to_select=2, step=1)
rfe_selector.fit(X, y)
X.columns[rfe_selector.get_support()]

4. Feature Selection via SelectFromModel
Similar to RFE, SelectFromModel selects features based on the importance attributes of a specified model, such as coef_ or feature_importances_. The features exceeding a certain threshold are retained.
Example:
from sklearn.feature_selection import SelectFromModel
sfm_selector = SelectFromModel(estimator=LogisticRegression())
sfm_selector.fit(X, y)
X.columns[sfm_selector.get_support()]
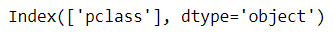
5. Sequential Feature Selection (SFS)
Newly introduced in Scikit-Learn 0.24, SFS is a greedy algorithm that either adds or removes features based on cross-validation scores. It evaluates the model's performance iteratively, selecting the best combination of features.
Here’s how to perform backward SFS:
from sklearn.feature_selection import SequentialFeatureSelector
sfs_selector = SequentialFeatureSelector(estimator=LogisticRegression(), n_features_to_select=3, cv=10, direction='backward')
sfs_selector.fit(X, y)
X.columns[sfs_selector.get_support()]
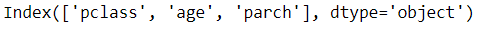
Conclusion
Feature selection is crucial in machine learning to ensure that only the most relevant features are utilized, thereby enhancing model accuracy and reducing complexity. In this article, we've covered five essential techniques available in Scikit-Learn: Variance Threshold, Univariate Selection with SelectKBest, Recursive Feature Elimination, SelectFromModel, and Sequential Feature Selection.
I hope you find these methods helpful in your projects! Feel free to connect with me on social media.